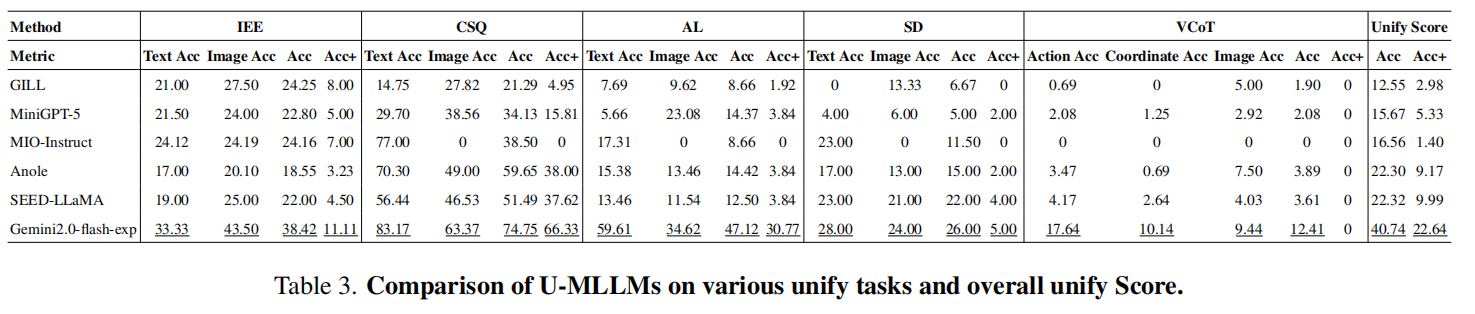
| # | Method | LLM | Date | Overall | Understanding | Generation | Unify | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task Split | Avg | SIPU | MTITU | VPU | Avg | CVIG | FIR | TIE | TIG | TVG | VP | Avg | IEE | CSQ | AL | SD | VCoT | Avg | |||||
| QA pairs | 1964 | 1200 | 400 | 364 | 1964 | 600 | 200 | 200 | 200 | 200 | 194 | 1594 | 200 | 100 | 52 | 104 | 90 | 546 | |||||
|
Gemini2.0-flash-exp
Google DeepMind |
- | 2025-03-12 | 45.6 | 72.6 | 68.3 | 54.9 | 65.2 | - | 77.6 | 43.5 | 57.6 | - | - | 29.8 | 38.4 | 74.8 | 47.1 | 26.0 | 12.4 | 40.7 | |||
|
MIO-Instruct
Beihang University |
MIO-7B | 2024-09-26 | 37.2 | 52.0 | 33.5 | 39.0 | 41.5 | 51.2 | 59.3 | 43.7 | 48.2 | 51.9 | 66.4 | 53.5 | 24.2 | 38.5 | 8.7 | 11.5 | 0 | 16.6 | |||
|
SEED-LLaMA
Tencent AI Lab |
LLaMA2-Chat-13B | 2023-12-18 | 28.5 | 49.2 | 33.0 | 36.3 | 39.5 | - | 57.0 | 42.3 | 42.0 | - | - | 23.5 | 22.00 | 51.5 | 12.5 | 22.0 | 3.6 | 22.3 | |||
|
Anole
GAIR |
- | 2024-07-08 | 18.6 | 17.2 | 14.5 | 9.0 | 13.6 | - | 36.6 | 43.4 | 41.5 | - | - | 20.0 | 18.6 | 59.7 | 14.4 | 15.0 | 3.9 | 22.3 | |||
|
VILA-U
Tsinghua University |
LLama-7B | 2024-09-06 | 18.6 | 51.0 | 32.3 | 36.5 | 40.0 | - | - | - | 45.1 | 49.6 | - | 15.8 | - | - | - | - | - | - | |||
|
Janus-Pro
DeepSeek-AI |
DeepSeek-LLM-7B-base | 2025-01-29 | 18.1 | 59.6 | 43.5 | 42.2 | 48.4 | - | - | - | 35.3 | - | - | 5.9 | - | - | - | - | - | - | |||
|
MiniGPT-5
University of California |
Vicuna-7B | 2023-10-03 | 16.4 | 19.3 | 10.9 | 15.9 | 15.4 | - | 39.0 | 35.0 | 35.5 | - | - | 18.3 | 22.8 | 34.1 | 14.4 | 5.0 | 2.1 | 15.7 | |||
|
Janus-Flow
DeepSeek-AI |
DeepSeek-LLM-1.5B-base | 2024-11-12 | 16.3 | 41.5 | 32.0 | 35.2 | 43.4 | - | - | - | 32.9 | - | - | 5.5 | - | - | - | - | - | - | |||
|
GILL
Carnegie Mellon University |
OPT-6-7B | 2023-03-26 | 15.1 | 22.2 | 6.0 | 3.6 | 10.6 | - | 50.7 | 35.7 | 46.6 | - | - | 22.2 | 24.3 | 21.3 | 8.7 | 6.7 | 1.9 | 12.6 | |||
|
HermesFlow
Peking University |
Phi-1.5 | 2025-2-17 | 14.0 | 41.5 | 33.0 | 28.3 | 34.3 | - | - | - | 46.5 | - | - | 7.8 | - | - | - | - | - | - | |||
|
Emu3
BAAI |
LLama-8B | 2024-09-27 | 13.8 | 45.8 | 30.5 | 23.3 | 33.2 | - | - | - | 49.1 | - | - | 8.2 | - | - | - | - | - | - | |||
|
Show-o
Show Lab |
Phi-1.5 | 2024-8-22 | 12.7 | 32.5 | 34.6 | 25.7 | 31.0 | - | - | 43.5 | - | - | 7.3 | - | - | - | - | - | - | ||||
Models are ranked according to their average performance on understanding, generation, and unify tasks, from highest to lowest.
SIPU: Single Image Perception & Understanding
TVG: Text-to-Video Generation
MTITU: Multiple & Interleaved Image-Text Understanding
VP: Video Prediction
VPU: Video Perception & Understanding
IEE: Image Editing and Explaining
CVIG: Conditional Image-to-Video Generation
CSQ: Common Sense Question Answering
FIR: Fine-grained Image Reconstruction
AL: Auxiliary Lines
TIE: Text-Guided Image Editing
SD: SpotDiff
TIG: Text-to-Image Generation
VCoT: Visual CoT
"Avg" indicates the average accuracy across subtasks in each domain.
"-" indicates that the model is unable to finish the corresponding task.
"Green date" indicates the newly added/updated models.